

Update, July 19, 2023
As promised, STM32AI – TAO Jupyter notebooks are now available for download on our GitHub page. We provide scripts to train, adapt, and optimize neural networks before processing them with STM32Cube.AI, which generates optimized code for our microcontrollers. It’s one of the most straightforward ways to experiment with pruning, retraining, or benchmarking, thus reducing the barrier to entry by facilitating the user of the TAO framework to create models that will run on our MCUs.
- Download STM32AI – TAO
What are the challenges behind machine learning at the edge?
Machine learning at the edge is already changing how systems process sensor data to alleviate the use of cloud computing, for example. However, it still has inherent challenges that can slow its adoption. Engineers must still deal with memory-constrained systems and stringent power efficiency requirements. Failure to account for them could prevent a product from shipping. Moreover, engineers must work with real-time operating systems, which demand a certain optimization level. An inefficient runtime could negatively impact the overall application and ruin the user experience. As a result, developers must ensure that their neural networks are highly optimized while remaining accurate.
How is ST solving this challenge?
STM32Cube.AI
To solve this challenge, ST came up with STM32Cube.AI in 2019, a tool that converts a pre-trained neural network into optimized code for STM32 devices. Version 7.3 of STM32Cube.AI introduced new settings that enabled developers to prioritize RAM footprint, inference times, or a balance between the two. It thus helps programmers tailor their applications. ST also introduced support for deeply quantized and binarized neural networks to reduce RAM utilization further. Given the importance of memory optimizations on embedded systems and microcontrollers, it’s easy to understand why STM32Cube.AI (now in version 8) has been adopted by many in the industry. For instance, we recently showed a people counting demo from Schneider Electric, which used a deeply quantized model.
STM32Cube.AI Developer Cloud and NanoEdge AI
To make Industrial AI applications more accessible, ST recently introduced the STM32Cube.AI Developer Cloud. The service enables users to benchmark their applications on our Board Farm to help them determine what hardware configuration would give them the best cost-per-performance ratio, among other things. Additionally, we created a model zoo to optimize workflows. It provides recommended neural network topologies based on applications to avoid memory limitations or poor performance down the road. ST also provides NanoEdge AI Studio that specifically targets anomaly detection and can run training and inference on the same STM32 device. The software offers a more hands-off approach for applications that don’t require as much fine-tuning as those that rely on STM32Cube.AI.
Ultimately, STM32Cube.AI, STM32Cube.AI Developer Cloud, and NanoEdge AI Studio put ST in a unique position in the industry as no other maker of microcontrollers provides such an extensive set of tools for machine learning at the edge. It explains why NVIDIA invited ST to present this demo when the GPU maker opened its TAO Toolkit to the community. Put simply, both companies are committed to making Industrial AI applications vastly more accessible than they are today.
STM32Cube.AI Developer Cloud and NanoEdge AI
To make Industrial AI applications more accessible, ST recently introduced the STM32Cube.AI Developer Cloud. The service enables users to benchmark their applications on our Board Farm to help them determine what hardware configuration would give them the best cost-per-performance ratio, among other things. Additionally, we created a model zoo to optimize workflows. It provides recommended neural network topologies based on applications to avoid memory limitations or poor performance down the road. ST also provides NanoEdge AI Studio that specifically targets anomaly detection and can run training and inference on the same STM32 device. The software offers a more hands-off approach for applications that don’t require as much fine-tuning as those that rely on STM32Cube.AI.
Ultimately, STM32Cube.AI, STM32Cube.AI Developer Cloud, and NanoEdge AI Studio put ST in a unique position in the industry as no other maker of microcontrollers provides such an extensive set of tools for machine learning at the edge. It explains why NVIDIA invited ST to present this demo when the GPU maker opened its TAO Toolkit to the community. Put simply, both companies are committed to making Industrial AI applications vastly more accessible than they are today.
How is NVIDIA solving this challenge?
TAO Toolkit
TAO stands for Train, Adapt, Optimize. In a nutshell, TAO Toolkit is a command-line interface that uses TensorFlow and PyTorch to train, prune, quantize, and export models. It allows developers to call APIs that abstract complex mechanisms and simplify the creation of a trained neural network. Users can bring their weighted model, a model from the ST Model Zoo, or use NVIDIA’s library to get started. The NVIDIA model zoo includes general-purpose vision and conversational AI models. Within these two categories, developers can select among more than 100 architectures across vision AI tasks, like image classification, object detection, and segmentation, or try application-based models, such as people detection or vehicle classification systems.
Overview of the TAO Toolkit workflow
The TAO Toolkit allows a developer to train a model, check its accuracy, then prune it by removing some of the less relevant neural network layers. Users can then recheck their models to ensure they haven’t been significantly compromised in the process and re-train them to find the right balance between performance and optimization. ST also worked on a Jupyter notebook containing Python scripts to help prepare models for inference on a microcontroller. Finally, engineers can export their model to STM32Cube.AI using the quantized ONNX format, as we show in the demo, to generate a runtime optimized for STM32 MCUs.
Using TAO Toolkit and STM32Cube.AI together
The ST presentation at the NVIDIA GTC Conference 2023 highlights the importance of industry leaders coming together and working with their community. Because NVIDIA opened its TAO Toolkit and because we opened our tool to its trained neural network, developers can now create a runtime in significantly fewer steps, in a lot less time, and without paying a dime since all those tools remain free of charge. As the demo shows, going from TAO Toolkit to STM32Cube.AI to a working model usable in an application is much more straightforward. What may have been too complex or costly to develop is now within reach.
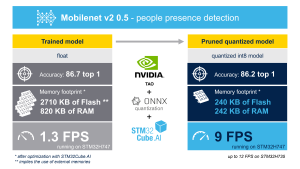
Using TAO Toolkit and STM32Cube.AI enabled a people detection application to run on a microcontroller at more than five frames per second, the minimum performance necessary. Below this threshold, people could run out of the frame before being detected. In our example, we also were able to decrease the Flash footprint by more than 90% (from 2710 KB to 241 KB) and the RAM usage by more than 65% (from 820 KB to 258 KB) without any significant reduction in accuracy. It will actually surprise many that the application takes more RAM than Flash, but that’s the type of optimization that microcontrollers need to play an important role in the democratization of machine learning at the edge.
The code in the demonstration is available in a Jupyter notebook downloadable from ST’s GitHub. In the video, you will see how developers can, with a few lines of code, use the STM32Cube.AI Developer Cloud to benchmark their model on our Board Farm to determine what microcontroller would work best for their application. Similarly, it shows how engineers can take advantage of some of the features in TAO Toolkit to prune and optimize their model. Hence, it’s already possible to prepare teams to rapidly take advantage of the new workflow once it is open to the public.




{kind=link}