
Tam Do, Technical Staff Engineer, Microchip Technology Inc.

Today’s Graphics Processing Units (GPUs) come with a significantly higher computational capacity. This results in the breakthrough of the bottleneck in the data path between storage and GPU memory and realizes optimum application performance. NVIDIA’s Magnum IO GPU Direct Storage solution helps achieve this by allowing a direct path between storage devices and GPU memory. It is important to note that this needs to be complemented by a fault-tolerant system to ensure the backup of critical data in case of a catastrophic failure. This can be achieved by connecting logical RAID volumes over PCIe® fabrics. Under the PCIe 4.0 specification, this action can increase data rates up to 26 GB/s.To accrue these benefits, let’s first look at the solution’s key components and how they work together to deliver their results.
Magnum IO GPU Direct Storage
Magnum IO GPU Direct Storage works effectively to remove one of the major performance bottlenecks since it does not use the system memory in the CPU to load data from storage into GPUs for processing. In general, data transfer from the GPU to the host’s memory relies on the bounce buffer, an area in CPU system memory. Multiple copies of data are created here before being transferred to the GPU. There is, however, considerable data movement on this route which results in latency and reduced GPU performance and uses several CPU cycles in the host. With the use of Magnum IO GPU Direct Storage, the need to access the CPU can be eliminated and ultimately removes the inefficiencies in the bounce buffer (figure 1).
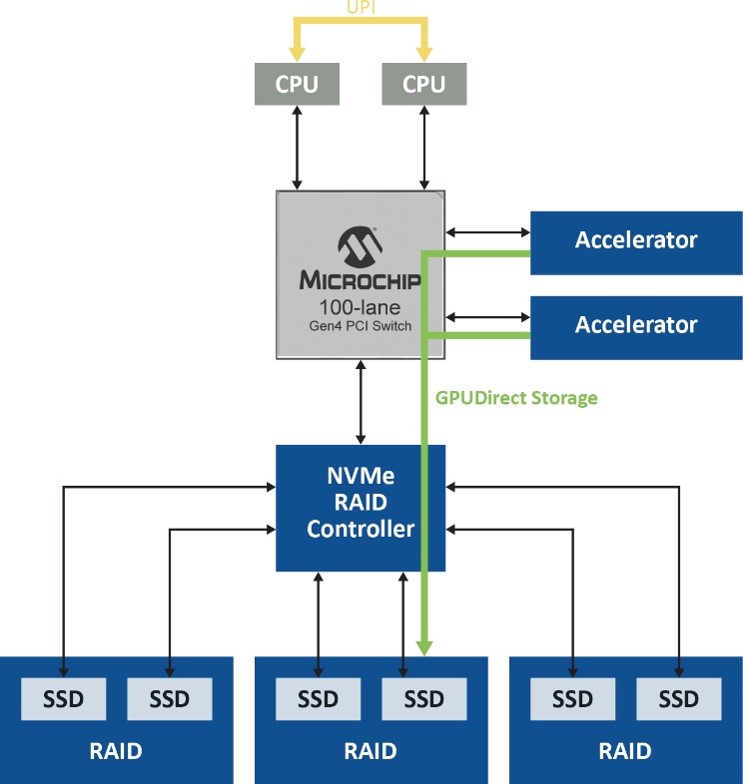
Figure 1. Magnum IO GPUDirect Storage removes the CPUs and thus bounce buffering from the data path.
The performance improvement is directly proportional to the amount of data transferred. The volume of data grows exponentially in the case of large and distributed datasets such as those required by artificial intelligence (AI), machine learning (ML), deep learning (DL) and other data-intensive applications. This approach allows quick access to petabytes of storage no matter the data is stored locally or remotely. This is faster than accessing the page cache in CPU memory.
Optimizing RAID Performance
The next challenge is to include RAID capabilities such that data redundancy and fault tolerance are maintained. Despite the ability of the software RAID to provide data redundancy, the underlying software RAID engine still utilizes the Reduced Instruction Set Computer(RISC) architecture for operations such as parity calculations. Hardware RAID is significantly faster than software RAID when we compare write I/O latency for advanced RAID levels such as RAID 5 and 6. This is because a dedicated processor is available in hardware RAID for these operations and write-back caching. However, software RAID’s long I/O response times pile up data in the cache in streaming applications. Cache data pile-up does not occur in hardware RAID solutions as they have dedicated battery backups to avoid data loss in the event of catastrophic system power failures.
The standard hardware RAID eases the parity management burden from the host. However, a lot of data still needs to pass through the RAID controller before being sent to the NVMe® drive. This results in more complex data paths. The NVMe-optimized hardware RAID can solve this by providing a streamlined data path unencumbered by firmware or the RAID-on-chip controller. Thus, hardware-based protection and encryption services can be maintained.
PCIe Fabrics in the Mix
While the PCIe Gen 4 is considered a fundamental system interconnected within storage subsystems, a standard PCIe switch still has the same basic tree-based hierarchy as in earlier generations. Therefore, host-to-host communications require non-transparent bridging (NTB) to cross partitions. This adds to the complexity, especially in multi-host multi-switch configurations. Microchip’s PAX PCIe Advanced Fabric switch is one of the solutions to these limitations as it supports redundant paths and loops, whereas traditional PCIe would not have been possible.
There are two discrete domains in a fabric switch, including the host virtual domain for each physical host and the fabric domain that contains all endpoints and fabric links. With the non-hierarchical routing of the traffic in the fabric domain, transactions from the host domains are translated into IDs and addresses in the fabric domain and vice versa. Thus, fabric links connecting to the switches and endpoints can be shared by all hosts in the system.
A PCIe-compliant switch, with a configurable number of downstream ports, is virtualized by the fabric firmware running on an embedded CPU. As a result, the switch always appears as a standard single-layer PCIe device with direct-attached endpoints irrespective of the location of the endpoints in the fabric. The fabric switch intercepts all configuration plane traffic from the host, including the PCIe enumeration process and chooses the best path. Thus, endpoints such as GPUs can bind to any host within the domain (figure 2).
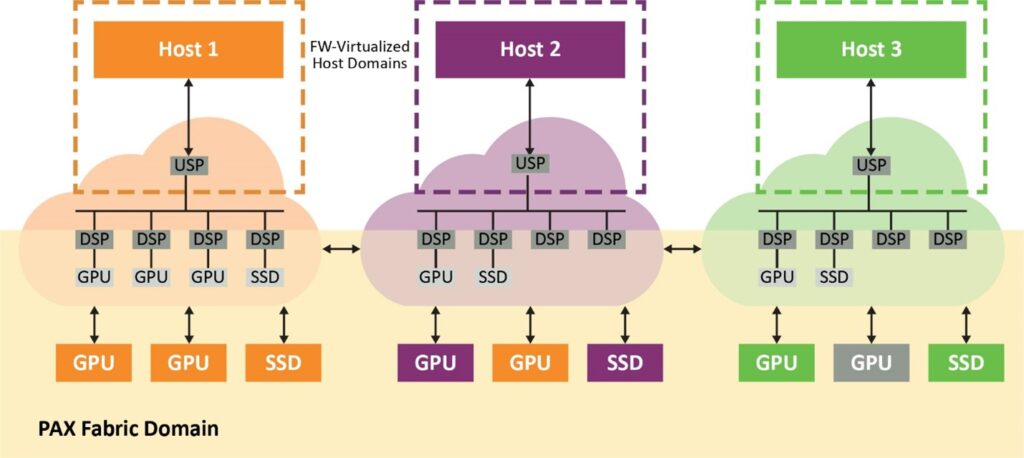
Figure 2.A switch firmware-virtualized host domain presented as a single-layer PCIe-compliant switch to each host.
In the two-host PCIe fabric engine setup (figure 3), each host can see a transparent PCIe topology with one upstream port, three downstream ports and three endpoints that are connected to them and enumerate them properly with fabric virtualization. Interestingly, we see in figure 3that there is a single root I/O virtualization (SR-IOV) SSD with two virtual functions. Microchip’s PCIe advanced fabric switch enables sharing of the virtual functions of the same drive with different hosts.
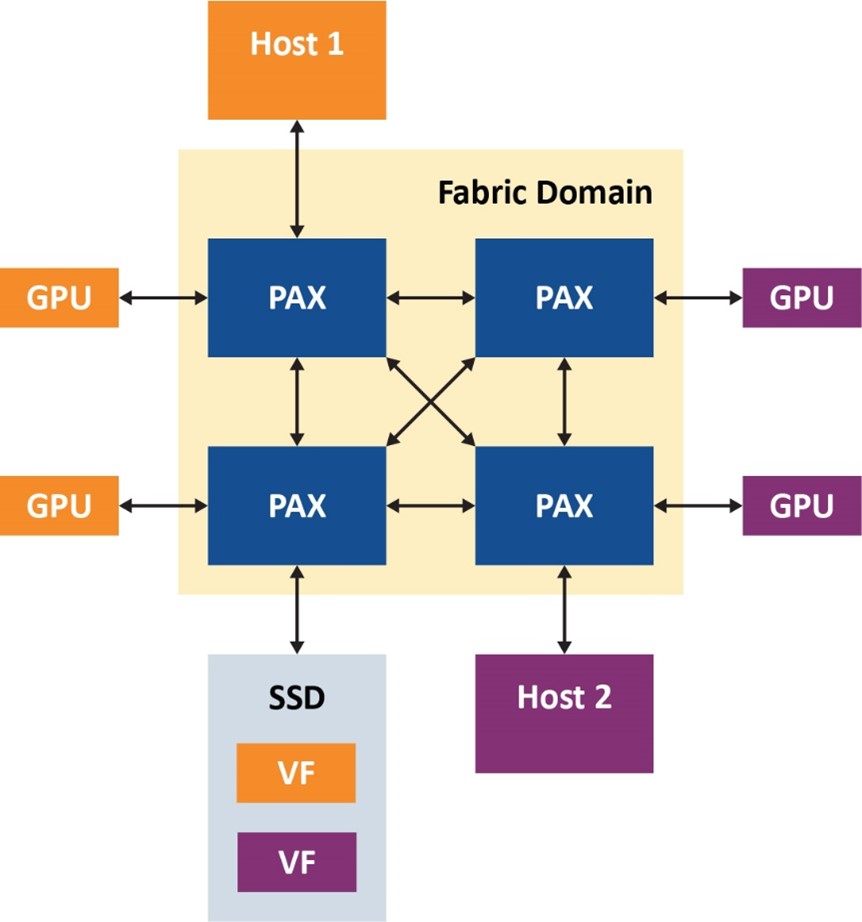
Figure 3. The two-host PCIe fabric engine
In addition, this PAX fabric switch solution enables direct cross-domain peer-to-peer transfers across the fabric. This decreases root port congestion and mitigates CPU performance bottlenecks as shown in figure 4.
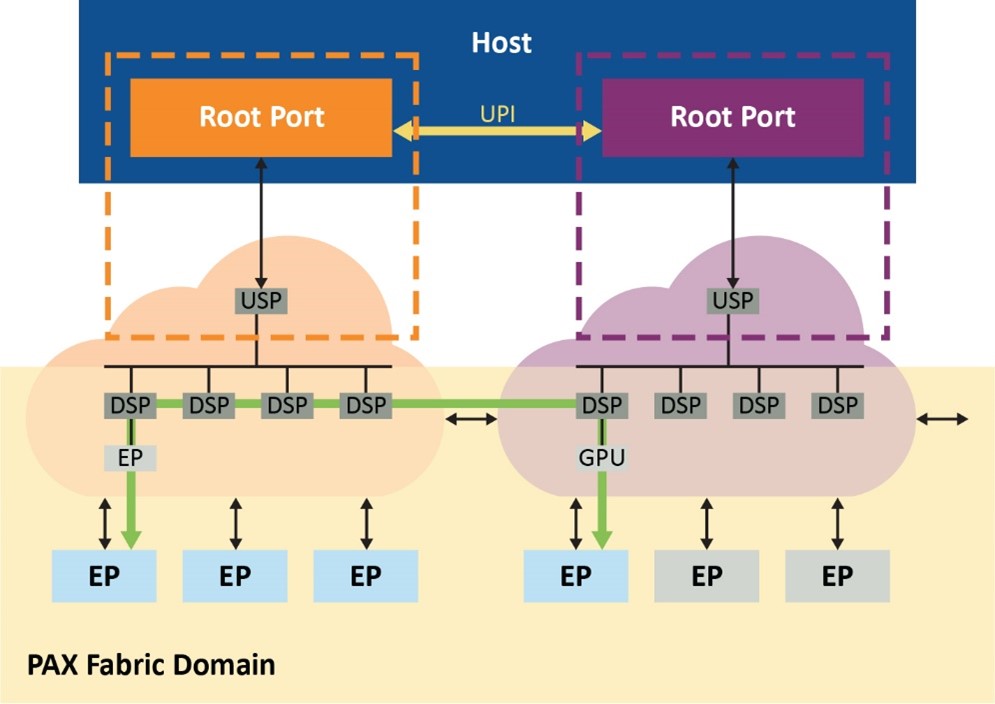
Figure 4. Traffic routed through the fabric decreases port congestion.
Performance Optimization
Based on the understanding of all the components involved in optimizing data transfer performance between NVMe drives and GPUs, they can be combined to reach the desired result. Figure 5 illustrates this by demonstrating the numerous steps showing the host CPUs and their root ports and various configurations that lead to the best result.
As figure 5 shows, the maximum data rate of PCI Gen 4 x 4 (4.5 GB/s) is limited to 3.5 GB/s even with a high-performance NVMe controller. This is due to the overhead through the root ports. However, when we simultaneously aggregate multiple drives via RAID (logical volumes) as shown on the right, the data rate increases to 9.5 GB/s. This is possible since the SmartRAID controller creates two RAID volumes each for the four NVMe drives and conventional PCIe peer-to-peer routing through the root ports.
In the case of a cross-domain peer-to-peer transfer (bottom figure), traffic is routed through the fabric link instead of the root port. This can achieve the highest speed of 26 GB/s using the SmartROC 3200 RAID controller. In the last scenario, the full potential of GPUDirect Storage is exploited. The switch still maintains the hardware-based protection and encryption services of RAID while supplying a straight data path that is not burdened by the firmware.
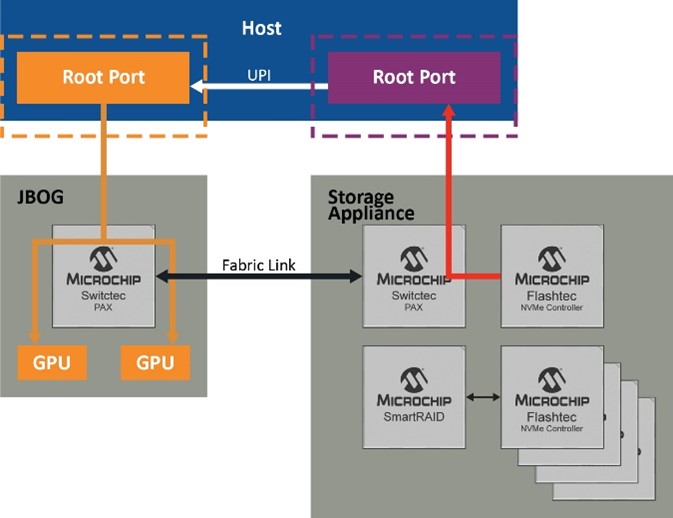
Figure 5. The path to achieving 26 GB/s
Conclusion
With high-performance PCIe fabric switches such as Microchip’s PAX, multi-host sharing of drives supporting SR-IOV and dynamically partitioning a pool of GPUs and NVMe SSDs to be shared among multiple hosts is possible. Microchip’s PAX fabric switch can also dynamically transfer endpoint resources to any host that needs them.
By using SmartPQI drivers supported by the SmartROC 3200 RAID controller family, the need for a custom driver is eliminated. Currently, Microchip’s SmartROC 3200 RAID controller delivers the highest possible transfer rate of 26 GB/s. Its other advantages include very low latency, availability of 16 lanes of PCIe Gen 4 for the host and backward compatibility with PCIe Gen 2.The full potential of PCIe and Magnum IO GPU Direct Storage can be leveraged when used with Microchip’s Flashtec® family-based NVMe SSDs in a multi-host system. Together, they make up a challenging system supporting AI, ML, DL and other high-performance computing applications in real time.




{kind=link}