
Performance is the accomplishment of a given task measured against the present known standard of accuracy, completeness, cost and speed. It has never been easy to compare different Microcontrollers based on their performance as there are hundreds of Microcontrollers available in the industry with different features/configurations for any specific application. Benchmarking is the solution for this tough challenge.
For almost one and half decades, Dhrystone benchmarking was the only benchmark for the MCU core. Dhrystone, a synthetic computing benchmark program was developed in 1984 by Reinhold P. Weicker and was intended to be representative of system (integer) programming. Dhrystone is a simple program that is carefully designed to statistically mimic the processor usage of certain common set of programs. Dhrystone may represent a result in a more meaningful manner than MIPS (Million Instructions Per Second) because instruction count comparisons between different instruction sets (e.g. RISC vs. CISC) can confound simple comparisons. For example, the same high-level task may require many more instructions on an RISC machine, but might execute faster than a single CISC instruction. Thus in comparison, the Dhrystone score counts only the number of program iteration completions per second, allowing individual machines to perform this calculation in a machine-specific way.
An ideal benchmark would provide a score that purely reflects the MCU’s core performance capabilities, irrespective of the rest of the system. But that is not possible as all MCU cores must interact with a different set of memory – the cache, data memory as well as the instruction memory which might not run at an optimum MCU core frequency. The MCU’s core performance is also linked with tool chains like compilers. Different compilers generate different codes for the same C code. Hence, the overall benchmarking should involve the MCU core, memory speed and compilers, which is not the case with Dhrystone benchmarking.
In 1996, Markus Levy had executed a hands on project intended to address the ineffectiveness of Dhrystone MIPS as a tool for evaluating embedded processor performance and for creation of a new set of benchmarks that would provide better information to aid in the analysis of microprocessors, microcontrollers, and compilers. In 1997 Markus Levy had proposed The EEMBC idea in a conference where attending companies included AMD, ARM, DEC, Hitachi, IBM, Intel, LSI Logic, Microchip, Motorola, National Semiconductor, NEC, Philips, SGS-Thomson, Siemens, Sun, TEMIC, Texas Instruments, and Toshiba, a number of these which would go on to become EEMBC’s original members. Six months later, with funding and legal approval from 12 initial members, EEMBC was founded as a non-profit industry-standard consortium. Since that time, EEMBC’s membership has expanded to more than 50 members and its benchmark suites have effectively replaced Dhrystone MIPS as the industry standard for measuring processor, DSP, and compiler performance. Some popular benchmarks of EEMBC are:
- CoreMark
- UPL Benchmark
- ScaleMark
- FP Benchmark
- Browsing Benchmark
- IoT Benchmark
- AndEBench-Pro
This article highlights Coremark and ULP Benchmarks which are readily available for the evaluation of MCU cores.
CoreMark
CoreMark is a small benchmark released by EEMBC that targets the CPU core. CoreMark avoids issues such as the compiler computing the work during compile time, and uses real algorithms rather than being completely synthetic. To appreciate the value of CoreMark, Lets discuss its testing components, which are lists, strings, and arrays (matrixes to be exact).
Lists
Lists are commonly exercised pointers and are also characterized by non-serial memory access patterns. In terms of testing the core of a CPU, list processing predominantly tests how fast data can be used to scan through the list. For lists larger than the CPU’s available cache, list processing can also test the efficiency of cache and memory hierarchy.
List processing consists of reversing, searching or sorting the list according to different parameters, based on the contents of the list data items. To verify correct operation, CoreMark performs a 16b cyclic redundancy check (CRC) based on the data contained in elements of the list. Since CRC is also a commonly used function in embedded applications, this calculation is included in the timed portion of the CoreMark. In many simple list implementations, programs allocate list items as needed with a call to malloc. However, on embedded systems with constrained memory, lists are commonly constrained to specific programmer-managed memory blocks. CoreMark uses the latter approach to avoid calls to library code (malloc/free).
Since pointers on CPUs can range from 8 bits to 64 bits, the number of items initialized for the list is calculated such that the list will contain the same number of items regardless of pointer size. In other words, a CPU with 8-bit pointers will use ¼ of the memory that a 32-bit CPU uses to hold the list headers).
Matrix Processing
Many algorithms use matrixes and arrays, require significant research on optimizing this type of processing. These algorithms test the efficiency of loop operations as well as the ability of the CPU and Compiler IDE to use ISA accelerators such as MAC units and SIMD instructions. CoreMark performs simple operations on the input matrixes, including multiplication with a constant, a vector, or another matrix. CoreMark also tests operating on part of the data in the matrix in the form of extracting bits from each matrix item for operations. To validate that all operations have been performed, CoreMark again computes a CRC on the results from the matrix test.
State machine processing
The CPU needs to handle control statements other than the loop. A state machine based on switch or if statement is an ideal candidate for testing that capability. There are 2 common methods for state machines – using switch statements or using a state transition table. Because CoreMark already utilizes the latter method in the list processing algorithm to test load/store behavior, CoreMark uses the former method, switch and ‘if’ statements, to exercise the CPU control structure.
The state machine tests an input string to detect if the input is a number, if it is not a number it will reach the “invalid” state. This is a simple state machine with 9 states. The input is a stream of bytes, initialized to ensure we pass all available states, based on an input that is not available at compile time. The entire input buffer is scanned with this state machine.
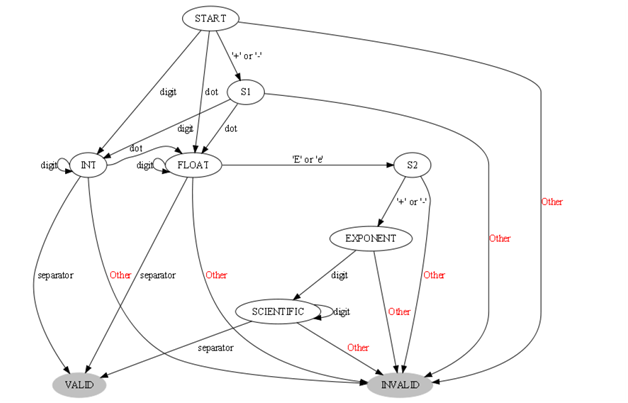
To validate operation, CoreMark keeps count of how many times each state was visited. During each iteration of CoreMark, some of the data is corrupted based on input that is not available at compile time. At the end of processing, the data is restored based on inputs not available at compile time.
In order to remain accessible to as many embedded systems as possible, big and small, the program has a 2 kb code footprint.
CoreMark Results:
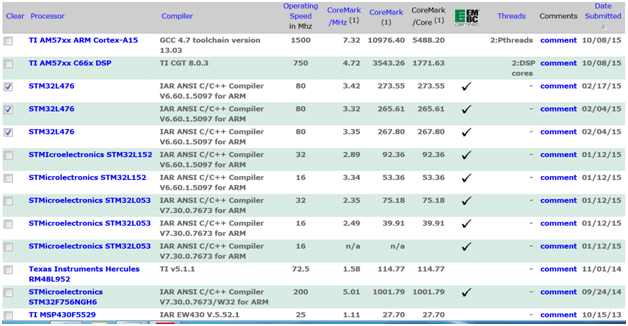
There are around 408 CoreMark results available online at http://www.eembc.org/coremark/index.php. These results are given as CoreMark, CoreMark/MHz and CoreMark/Core ( bigger is better) with compiler version, operating speed.
You can note that for STM32L476 with same compilers and the same operating speed, there are three different results. By selecting them, you can view these results in detail and can find that the code was running with different memory options. So with CoreMark, we find a detailed benchmarking of MCU.
UPL Benchmark
In any IOT / battery-powered equipment, power is one of the most critical specifications while designing a product. Depending on the application, the criterion for selection of the device varies. In most of such applications, the system spends most of its time in sleep mode and only at prescribed events, it wakes up and works as per the system requirement. So depending on the ratio of the active and standby/sleep time, the designer has to select the components based on Active/Sleep current. Overall, the application requires a combination of, or tradeoffs on all of the above.
However in most of the applications, a CPU is not the only energy consumer. Peripherals can contribute significantly to the total energy consumption. This makes it harder to create benchmarks since peripherals vary widely between microcontroller vendors and even between multiple platforms from the same vendor. So a benchmark code must be developed in a manner that allows flexibility and easy adoption or integration into any microcontroller system. The next important power contributor is the frequency at which the MCU wakes up from standby modes.
In any low power application, the active mode duty cycle should be as low as possible and the system should remain in sleep mode most of the time. However this needs to be balanced with the real-time needs of the system. For example, the systems may have a calendar function that needs to update every second. Another example to consider is industrial sensors requiring a collection of ADC samples at a rate of 1 ksps, following which the data is evaluated and processed. The ULPBench benchmark used a 1 second wake up interval. This interval serves the purpose of providing a reasonable power-down time while also incorporating the energy budget required in moving the system in and out of power-saving modes. The energy budget during wakeup is not always specified directly in MCU datasheets and is therefore a useful part of the benchmark evaluation.
The benchmark suite is being built in several developmental phases. The first phase – CoreProfile, covers the CPU, memory access, real-time clock and power-saving features. CoreProfile is applicable to a large number of applications and provides a valuable means to compare various MCUs. In CoreProfile, the defined base rule states that a ULP application needs to be able to run off one CR2032 battery [with capacity of 225 mAh] for more than four years. The typical application profile has at least one active phase per second and performs predefined tasks in this active phase.
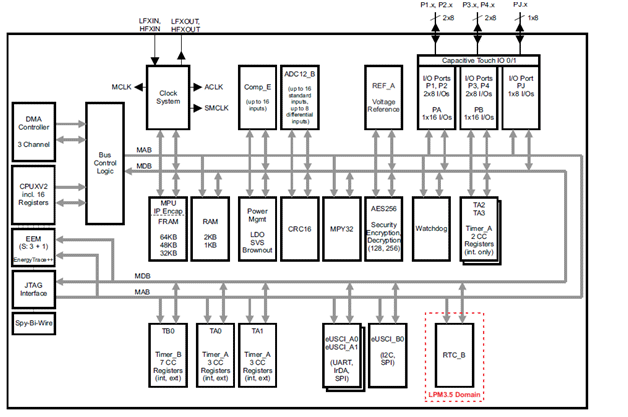
The MCU’s hardware requirements to run CoreProfile are as follows:
– CPU, RAM, non-volatile program memory
– RTC timer/counter for one second wake-up interrupt
– 32kHz oscillator for RTC
– Reset circuit for proper startup
– Power supply range that includes 3V
The CoreProfile benchmark has two modes. The first is active mode where the CPU performs a predefined set of functions. The second is the power-saving mode where the CPU remains in standby and the RTC wakes up the CPU once per second to re-run the predefined task.
The ULPBench benchmark will provide a set of profiles orientated towards various real-world applications. Based on these profiles, users can identify and scale their application requirements and analyse the amount of energy the target application can be expected to consume for a given microcontroller.
TI in this field:
When profiling TI’s ultra-low-power MSP430 family of microcontrollers, a considerable variance in the benchmark score can be observed when executing CoreProfile. These variations in the ULPBench score are driven by various factors which influence the energy consumption while executing the specified task, but also from the capability to save energy during the power saving phase and the transitions in-between. Some other factors that can impact the score are memory size (and the associated load on the address and data bus), process technology and supply rail (digital core powered by widely varying supply rail vs. LDO regulated voltage).
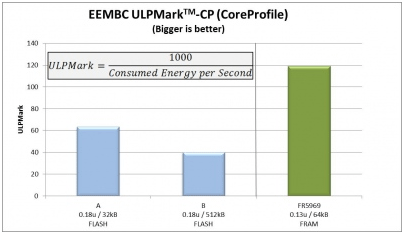
As seen from the below Figure, the MSP430FR5969 MCU based on TI’s ultra-low-leakage FRAM process technology using the intelligent power management system provides a very compelling ULPBench CoreProfile score that proves its intrinsic ability to meet the strictest energy budgets across a wide variety of applications.
ULPBench benefits
ULPBench is the first comprehensive benchmark that allows developers to use an impartial method to compare various ultra-low-power microcontrollers based on the energy consumption during the real-time execution of a predefined task. Any MCU vendor can provide the benchmark ported to their specific MCU architecture and also provide best practices to optimise their code for achieving the best results. Vendors can also provide hardware (e.g. peripheral) and software (e.g. compiler) settings used in the process of benchmarking. Developers can thus save time and effort spent in understanding energy optimisation methods and simply use the ULPBench code provided by vendors as the ‘golden standard’ for lowest energy consumption. This helps the MCU evaluation process become faster, more portable, more efficient and unbiased.
Future ULPBench profiles
CoreProfile is the first phase in a suite of benchmark profiles for ultra-low-power applications. The second phase, called Peripheral Profile will add specific peripheral accesses and functionalities to the energy benchmark suite. This profile will look to cover ADC conversions, PWM generation, SPI communication and RTC functionality.
About Author





{kind=link}