
Everyone is talking about Coverage Driven Verification and everyone wants to go random. Randomization leads to requirement for constrained transactions. Considering couple of common tit bits; ensures that constraints are written properly and behaves as we intend them to; without overloading the constraint solver. This saves the critical time during coverage closure and helps to cut the time tool’s constraint solver consumes. This paper explains simple considerations for commonly used SystemVerilog constraints.
Index Terms:
CDV (Coverage Driven Verification)
CRV (Constrained Random Verification)
HDVL (High level Design & Verification Language)
UVM (Universal Verification Methodology)
RNG (Random Number Generator)
I. INTRODUCTION:
The terms CRV and CDV go hand in hand. CRV generates all sort of random traffic and CDV measures its effectiveness in terms of functionality covered. The HDVL SystemVerilog has a fairly rich set of constructs to support both Constraints and Coverage. The idea here is to generate the input stimulus to the DUT in a random manner but within constrained legal ranges. The register configuration can also be optionally randomized. This simulates the DUT rigorously and many times helps to hit corner cases that neither verification engineers nor designers thought of. At the same time, it is very important to identify right technique and right amount of randomization needed to verify a feature. Excessive randomization might result in creating illegal scenarios and long constraint solver overhead which ultimately results in loss of valuable verification time. Also, the constraints should be written carefully so as to target right scenarios and not overload the constraint solver.
The paper moves on to cover various tit bits for implementing common constraints in SystemVerilog. The examples mentioned here are simulated using vcs 2013.06 with a seed 1.
II. COMMON RANDOM CONSTRAINTS CONSIDERATIONS:
Let’s learn and understand some common SV constraints that can help to develop and debug constraints.
(1) Randomization requirement depends on the complexity of logic/protocol being verified and the scope of verification. We might need to go for layered constraints to realize various legal/corner/illegal scenarios. SV features “soft” constraint that is useful for layered constraints.
Example (1) shows 4 classes. For “register_legal” and “register_illegal”, the name of the constraint “reg_data_cons” is same as that in “register”. Hence, while randomizing, solver will overwrite the default constraint in “register” and will generate “reg_data” as per the overwritten constraint in the derived class. For “register_illegal_1”, the constraint name is different than that in the “register” class. Hence, while randomizing, the solver will see two contradicting constraints and will give ERROR.

To handle this, SV provides “soft” constraints. Example (2) shows its usaget. “soft” constraints will be overwritten if any contradiction occurs.

(2) Seed Stability is a very important aspect for any CRV/CDV based Verification. We should be able to reproduce the failure with the same seed. As the source code keeps changing, there is no guarantee that same scenario will be regenerated with the same seed. Hence, it is important to take advantage of SV’s thread and object stability and update the source code so as to retain the seed stability.
The randomly generated values depend on the RNG provided by the simulator. For SV, seeding is done hierarchically. Firstly, every module/program/interface instance and package gets a RNG initialized. Every new instantiated object or thread gets a new RNG based on the sequence in which they are created. Once created, the random values generated in that thread or for that object remains independent of other RNG for other threads and objects.
Example (3)(4)(5) illustrates object stability. Look to the output generated for this code.
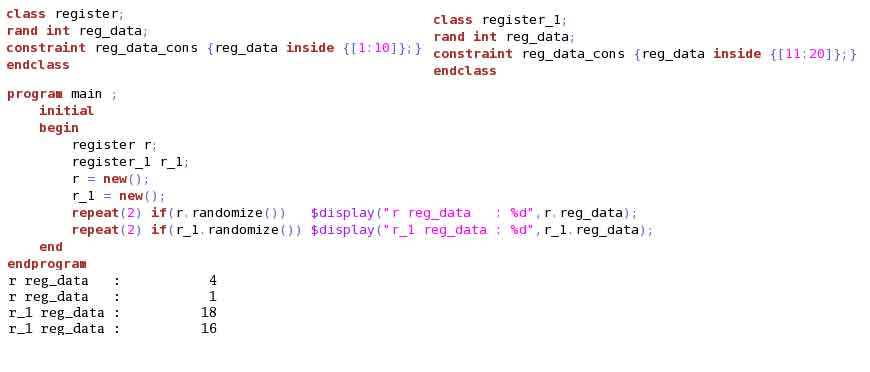
Without changing any code, if we just swap the call to randomization, the output remains same. This is because, simulator assigns a RNG when the object is created and the stream of random values generated for this object will be based on this initial RNG. Example (4) illustrates this.

Without changing any code, if we just swap the creation of “r” and “r_1”, output generated is different. This is because, we swapped the object creation and hence RNG assigned to the object changed. Example (5) illustrates this. Hence, whenever we update the code to add a new creation of object, make sure to add it at the end.

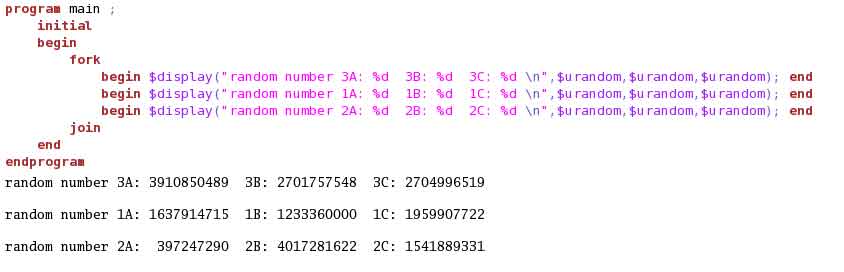
Example (6)(7)(8) illustrates thread stability. Look to the output generated for the code.

Simulator assigns a RNG to both threads spawned in the fork-join. Based on this RNG, each thread will generate its own stream of random values. Even if we add a new call to $urandom in each thread, the RNG for each thread remains unchanged and the stream of random data generated remains same. Example (7) illustrates this.

Adding a new thread before any previous thread will affect the RNG for the threads and hence will change the random values generated. Example (8) adds a new thread to the fork-join above previous threads. This changes the output stream. Hence, whenever we update the code to add a thread, make sure to add it at the end.
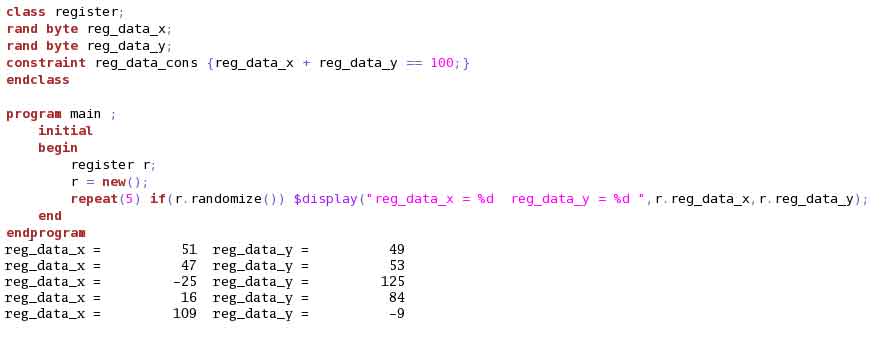
(3) Unintentionally used Signed datatypes in random generation are risky. We unknowingly use signed datatypes like int and byte. These datatypes when not properly constrained may yield negative numbers. As a safe guard, it is a better approach to use bit[x:0] where x is as per the desired range of values. This not only helps to generates numbers correctly but is also memory efficient.
Example (9) illustrates the behaviour when byte is used as datatype. Note the generation of negative numbers.
Example (10) illustrates the behaviour with same seed when datatype is changed to bit[6:0].
![Example (10) : Signed/UnSigned Consideration output with datatype as bit[6:0]](http://electronicsmaker.com/wp-content/uploads/2014/07/example_10.jpg)
(5) Dynamically TurnOff unnecessary constraint blocks and random variables to relieve the solver and aid simulation speed. Example (11) shows the usage of system tasks “constraint_mode(0/1)” and “rand_mode(0/1)” for this.

When constraint block “reg_data_y_cons” is turned off, this constraint become inactive and has no effect when “randomize()” is called.
Usage of “rand_mode(0/1)” needs some care. When you turn off randomization for “reg_data_y”, it no longer remains a random variable and will take the default value as per datatype. It is my observation that some simulator requires turning off for the corresponding variable’s constraint block as well. This is because it shows constraint conflict when a variable is non-random but its constraint block is active. Example (11) shows the “reg_data_y_cons” also turned off along with variable “reg_data_y”.
III. CONCLUSION:
Constraint is very powerful SV tool. Ensuring proper usage and taking care of certain common considerations ensures effective generation of expected scenario and reduces iterations to get the desired stimulus and coverage.
IV. REFERENCES:
[1] SystemVerilog_3.1aLRM
[2] Chapter 6: Randomization
Available: https://moodle.polymtl.ca/pluginfile.php/80905/course/section/16621
Author profile:
Heena Mankad is working with eInfochips as a Senior project engineer.She specializes in ASIC verification based on SV/UVM. She has worked on ASICs from TestPlan, Environment Architecture to Verification SignOff. She has also worked on cycle accurate C++ modeling and post silicon validation.” She is a gold medallist M.Tech in VLSI Design.
She can be reached at: heena.mankad@einfochips.com



